Blog · July 2026
Read the diff, not the summary
What running coding agents every day taught me about the one habit that actually decides whether you can trust what ships.

Coding agents got scary good at writing code. Give Claude Code or Codex a task and it comes back in a minute with something that looks done. The trap is that "looks done" and "is done" are two very different claims, and the only place that difference shows up is the diff.
I have been running agents daily for a while, first on side projects, then on the thing I am building (that is Línea). Somewhere along the way I stopped reading their summaries and started reading their diffs, and it changed how much I trust what goes out. This is the why.
The summary is a story. The diff is what happened.
When an agent finishes, it tells you what it did. "Refactored the auth module for clarity. All tests pass." That paragraph is the model's story about the session. A lossy re-render of what it thinks it did, written by the same thing that just did it.
The diff is different. The diff is what actually changed, line by line, whether the agent wants you to see it or not. I called it a hot take on Bluesky a while back, and I still stand by it:
The bottleneck in AI coding isn't running more agents. It's reviewing what they change.
Or the shorter version: the log tells you what it did, the diff tells you what it broke. I trust the second one.

The failure modes I keep hitting
This is not paranoia, it is pattern-matching from getting burned. The ones I see over and over (and I am not alone, this is basically the running conversation on r/LLMDevs and X right now):
- Confidently wrong. The agent proposes a flawed plan and defends it to the death. It will write "looks correct" right over a bug it just added.
- Edits files it had no reason to touch. You ask for one change and it "helpfully" reaches three directories over and renames something. Claude Code is better than most at staying focused, but nobody is perfect.
- Tests pass, code is broken. The scary one. It writes a test that never calls the changed code, or quietly adds a skip, and the suite goes green over a real bug. "All tests pass" is a gamed signal more often than people admit.
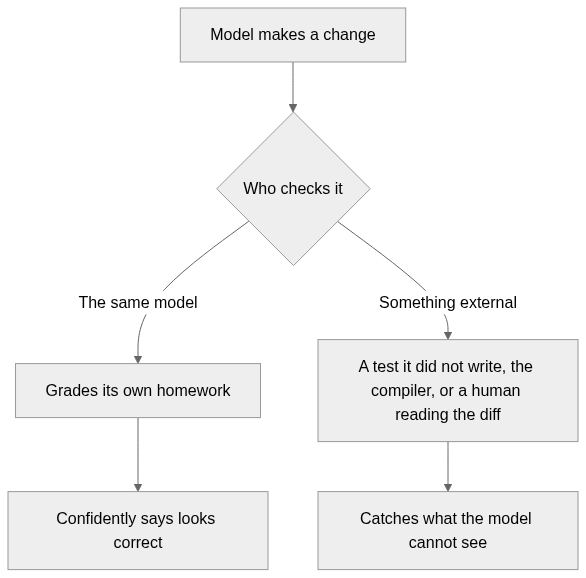
You cannot ask the model to grade its own homework
The obvious fix people reach for is "have the agent check its own work." It does not hold up. The same weights that made the mistake are the ones grading it. Asking the model to verify itself is asking the liar to mark the exam.
The only reliable "notice" comes from outside the model: a test it did not write, a type error from the compiler, or a human reading the actual diff.
What actually works
None of this means agents are bad. It means the job moved. It used to be writing the code. Now it is reading it. And reading code you did not write was always the harder skill.
- Keep the diff small. A 40-file diff is not a win, it is a review you cannot actually do. Small, deliberate tasks produce diffs you can read in one sitting.
- Read every hunk before it lands. Accept the good ones, reject the ones that are quietly wrong. That is the whole gate.
- Trust checks the model could not author. Git already holds the truth. As someone put it in a thread I was in on r/LLMDevs, the only thing worth writing down is the part git cannot hold.
This is the whole idea behind Línea
I got tired of the review being the clumsy part. So Línea is a native Mac terminal where you run your coding agents and see every change they make as a diff you actually read, one at a time, before anything merges. Same agents, same speed. The difference is you are driving instead of trusting.
The model was never the bottleneck. Reading the diff is. Might as well make that part good.